Complete Features
These features were completed when this image was assembled
Epic Goal
- Complete the implementation for AWS STS, including support and documentation.
Why is this important?
- Many customers want to follow best security practices for handling credentials.
- This is the way recommended by AWS.
- Customer interest: EMEA, AMER
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
Open questions:
- Will this cover existing OCP deployments or only new OCP deployments?
- Is there a migration path for existing customers to start using AWS STS?
- Are there considerations that apply to Operators so they can work with limited privilege credentials?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
The tool should be able to upload an OpenID Connect (OIDC) configuration to an S3 bucket, and create an AWS IAM Identity Provider that trusts identities from the OIDC provider. It should take infra name as input so that user can identify all the resources created in AWS. Make sure that resources created in AWS are tagged appropriately.
Sample command with existing key pair:
tool-name create identity-provider <infra-name> --public-key ./path/to/public/key
Ensure the Identity Provider includes audience config for both the in-cluster components ('openshift') and the pod-identity-webhook ('sts.amazonaws.com').
ccoctl should be able to delete AWS resources it created
ccoctl delete <infra-name>
Epic Goal
- Support running the image registry services in single-node OpenShift configurations for production use in edge computing use cases.
Why is this important?
- Some bare metal edge customers, especially in the telco market, want to use kubernetes at physically remote sites with minimal hardware.
Scenarios
- As a user, I want to deploy a fully supported instance of OpenShift on a single node.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
Dependencies (internal and external)
- ...
Previous Work (Optional):
- https://github.com/openshift/enhancements/pull/504
- https://github.com/openshift/enhancements/pull/560
- OCP Single Node Production Edge Profile
- We're pretty sure we need the node-ca deployed since our first few customers are using disconnected environments.
- It's not clear if we need the image-registry and image-pruner.
Open questions::
- ...
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
As a OpenShift administrator
I want the registry operator to use topology mode from Infrastructure (HighAvailable = 2 replicas, SingleReplica = 1 replica)
so that it the operator is not spending resources for high-availability purpose when it's not needed.
See also:
https://github.com/openshift/enhancements/blob/master/enhancements/cluster-high-availability-mode-api.md
https://github.com/openshift/api/pull/827/files
Number of replicas on different platforms
| Platform | SingleReplica | HighAvailable |
|---|---|---|
| AWS | 1 replica | 2 replicas |
| Azure | 1 replica | 2 replicas |
| GCP | 1 replica | 2 replicas |
| OpenStack (swift) | 1 replica | 2 replicas |
| OpenStack (cinder) | 1 replica | 1 replica (PVC) |
| oVirt | 1 replica | 1 replica (PVC) |
| bare metal | Removed | Removed |
| vSphere | Removed | Removed |
Epic Goal
- Support running console in single-node OpenShift configurations for production use in edge computing use cases.
- Support disabling the console entirely in some of these configurations to reduce overhead in constrained environments.
Why is this important?
- Some bare metal edge customers, especially in the telco market, want to use kubernetes at physically remote sites with minimal hardware.
Scenarios
- As a user, I want to deploy a fully supported instance of OpenShift on a single node.
Acceptance Criteria
- CI - MUST be running successfully with tests automated
- Release Technical Enablement - Provide necessary release enablement details and documents.
- console can be deployed with a single replica
Dependencies (internal and external)
Previous Work (Optional):
- https://github.com/openshift/enhancements/pull/504
- https://github.com/openshift/enhancements/pull/560
Open questions::
- Should the console configuration API have a separate option for this setting, or should it use the API created from
CORS-1589?
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
https://github.com/openshift/enhancements/pull/555
https://github.com/openshift/api/pull/827
The console operator will need to support single-node clusters.
We have a console deployment and downloads deployment. Each will to be updated so that there's only a single replica when high availability mode is disabled in the Infrastructure config. We should also remove the anti-affinity rule in the console deployment that tries to spread console pods across nodes.
The downloads deployment is currently a static manifest. That likely needs to be created by the console operator instead going forward.
Acceptance Criteria:
- Console operator deploys console with 1 replica and no anti-affinity rules when not in high availability mode
- Console operator deploys the downloads deployment with 1 replica when not in high availability mode
- The console and downloads deployments do not change when in high availability mode
- The feature is well-covered by tests
Bump github.com/openshift/api to pickup changes from openshift/api#827
Research if we can dynamically reserve memory and CPU for nodes.
Feature Overview
This will be phase 1 of Internationalization of the OpenShift Console.
Phase 1 will include the following:
- UI based language Selector instead of using browser detection
- Externalize all hard coded strings in the client code including all OpenShift static plugins
- Admin Console
- Dev Console
- Serverless
- Pipelines
- CNV
- OCS
- CSO
- Localized Date\Time
- Setup all processes, infrastructure, and testing required
- We will start with support for Chinese and Japanese lang
Phase 1 will not include:
- Dynamically generated UI (Operator, OpenAPIV3Schema)
- Operators that surface informational messages may not have translations available
- Strings from non client code
- This may include items such as events surfaced from Kuberenetes, alerts, and error messages displayed to the user or in logs
- Localization of logging messages at any level is not in scope
- Any CLI
- Language support for left to right languages ie Arabic
Initial List of Languages to Support
---------- 4.7* ----------
- Japanese - Code: ja
- Chinese - Code: zh_CN, zh_TW
- Korean - Code: ko
*This will be based on the ability to get all the strings externalized, there is a good chance this gets pushed to 4.8.
---------- Post 4.7 ----------
- Spanish: - Code: es_419, es
- German: - Code: de
- French - Code: fr
- Italian - Code: it
- Portuguese - Code: pt_BR
- Korean - Code: ko
- Hindi - Code: hi
POC
Goals
Internationalization has become table stakes. OpenShift Console needs to support different languages in each of the major markets. This is key functionality that will help unlock sales in different regions.
Requirements
| Requirement | Notes | isMvp? |
|---|---|---|
| Language Selector | YES | |
| Localized Date. + Time | YES | |
| Externalization and translation of all client side strings | YES | |
| Translation for Chinese and Japanese | YES | |
| Process, infra, and testing capabilities put into place | YES | |
| CI - MUST be running successfully with test automation | This is a requirement for ALL features. | YES |
Out of Scope
- Dynamically generated UI (Operator, OpenAPIV3Schema)
- Operators that surface informational messages may not have translations available
- Strings from non client code
- This may include items such as events surfaced from Kuberenetes, alerts, and error messages displayed to the user or in logs
- Localization of logging messages at any level is not in scope
- Any CLI support
- Language support for left to right languages ie. Arabic
Assumptions
- Each static plugin team will be responsible for externalizing all their client code strings.
- Quick Starts will need to be translated.
Customer Considerations
We are rolling this feature in phases, based on customer feedback, there may be no phase 2.
Documentation Considerations
I believe documentation already supports a large language set.
Epic Goal
- This is the continuation of the Internationalization work... the following items remain:
-
- All existing QuickStarts get Translated
- Automation Completed
- Any remaining items cleaned up
Why is this important?
- Automating as much as possible with the detecting duplicate strings, building, translation drops will ensure we will be successful for all future releases
- Quick Start are important part of the product that enable our users to maximize usage of the Console
- Best to clean up anything left over to reduce future Tech Debt
Acceptance Criteria
- Quick Starts are translated
- Everything is automated for building, and pushing translation drops to the globalization team
- Source code should be up to quality standards
Previous Work (Optional):
Done Checklist
- CI - CI is running, tests are automated and merged.
- Release Enablement <link to Feature Enablement Presentation>
- DEV - Upstream code and tests merged: <link to meaningful PR or GitHub Issue>
- DEV - Upstream documentation merged: <link to meaningful PR or GitHub Issue>
- DEV - Downstream build attached to advisory: <link to errata>
- QE - Test plans in Polarion: <link or reference to Polarion>
- QE - Automated tests merged: <link or reference to automated tests>
- DOC - Downstream documentation merged: <link to meaningful PR>
We have too many namespaces if we're loading them upfront. We should consolidate some of the files.
Consolidate namepsaces K-M to reduce change size
Consolidate namepsaces S-Z to reduce change size
Just do namespaces from A-D to reduce number of files being changed at once
Consolidate namepsaces E-I to reduce change size
Consolidate namepsaces N-R to reduce change size
We need to automate how we send and receive updated translations using Memsource for the Red Hat Globalization team. The Ansible Tower team already has automation in place that we might be able to reuse.
Acceptance Criteria:
- We have a script that takes the current messages from the console repos and pushes them to Memsource
- We have a script that pulls the updated translations from Memsource and creates a PR against openshift/console
- We work with the DPTP team to determine if this process can be automated such that it runs periodically (e.g. once a sprint)
Feature Overview
Openshift Sandboxed Containers provide the ability to add an additional layer of isolation through virtualization for many workloads. The main way to enable the use of katacontainers on an Openshift Cluster is by first installing the Operator (for more information about operator enablement check [1]).
Once the feature is enabled on the cluster, it just a matter of a one-liner YAML modification on the pod/deployment level to run the workload using katacontianers. That might sound easy for some, but for others who don't care about YAML they might want more abstractions on how to use katacontainers for their workloads.
This feature covers all the efforts required to integrate and present Kata in Openshift UI (console) to cater to all user personas.
Background, and strategic fit
To enable for users to adopt Kata as a runtime, it is important to make it easy to use. Adding hook-points in the UI with ease-of-use as a goal in mind is one way to bring in more users.
Goal(s)
The main goal of this feature is to make sure that:
- It is easy for users to find out how to use/enable Openshift Sandboxed Containers on their clusters (e.g., Getting started guide in the UI).
- Cluster-admins are able to differentiate between normal pods and Kata pods.
- Developers (application, CNF, ...) have an easy way to create Katacontiners (without peeking at YAMLs)
- Application End-users are able to collectively activate kata on their app packages/content (e.g., Helm, odo,...)
Documentation Considerations
Questions to be addressed:
- What educational or reference material (docs) is required to support this product feature? For users/admins? Other functions (security officers, etc)?
- Does this feature have doc impact?
- New Content, Updates to existing content, Release Note, or No Doc Impact
- If unsure and no Technical Writer is available, please contact Content Strategy.
- What concepts do customers need to understand to be successful in [action]?
- How do we expect customers will use the feature? For what purpose(s)?
- What reference material might a customer want/need to complete [action]?
- Is there source material that can be used as a reference for the Technical Writer in writing the content? If yes, please link if available.
- What is the doc impact (New Content, Updates to existing content, or Release Note)?
References
[1] https://issues.redhat.com/browse/KATA-429?jql=project %3D KATA AND issuetype %3D Feature
Goal
The grand goal is to improve the usability of Kata from Openshift UI. This EPIC aims to cover only a subset that would help:
- Make it easy to differentiate between native cluster runtime (e.g., runC) and kata.
- Enable Kata as a runtime without modifying YAMLs.
To use a different runtime e.g., Kata, the "runtimeClassName" will be set to the desired low-level runtime. Also please see [1]:
"RuntimeClassName refers to a RuntimeClass object in the node.k8s.io group, which should be used to run this pod. If no RuntimeClass resource matches the named class, the pod will not be run. If unset or empty, the "legacy" RuntimeClass will be used, which is an implicit class with an empty definition that uses the default runtime handler. More info: https://git.k8s.io/enhancements/keps/sig-node/runtime-class.md This is a beta feature as of Kubernetes v1.14.."
apiVersion: v1 kind: Pod metadata: name: nginx-runc spec: runtimeClassName: runC
The value of the runtime class cannot be changed on the pod level, but it can be changed on the deployment level
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandboxed-nginx
spec:
replicas: 2
selector:
matchLabels:
app: sandboxed-nginx
template:
metadata:
labels:
app: sandboxed-nginx
spec:
runtimeClassName: kata. # ---> This can be changed
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
protocol: TCP
User-stories
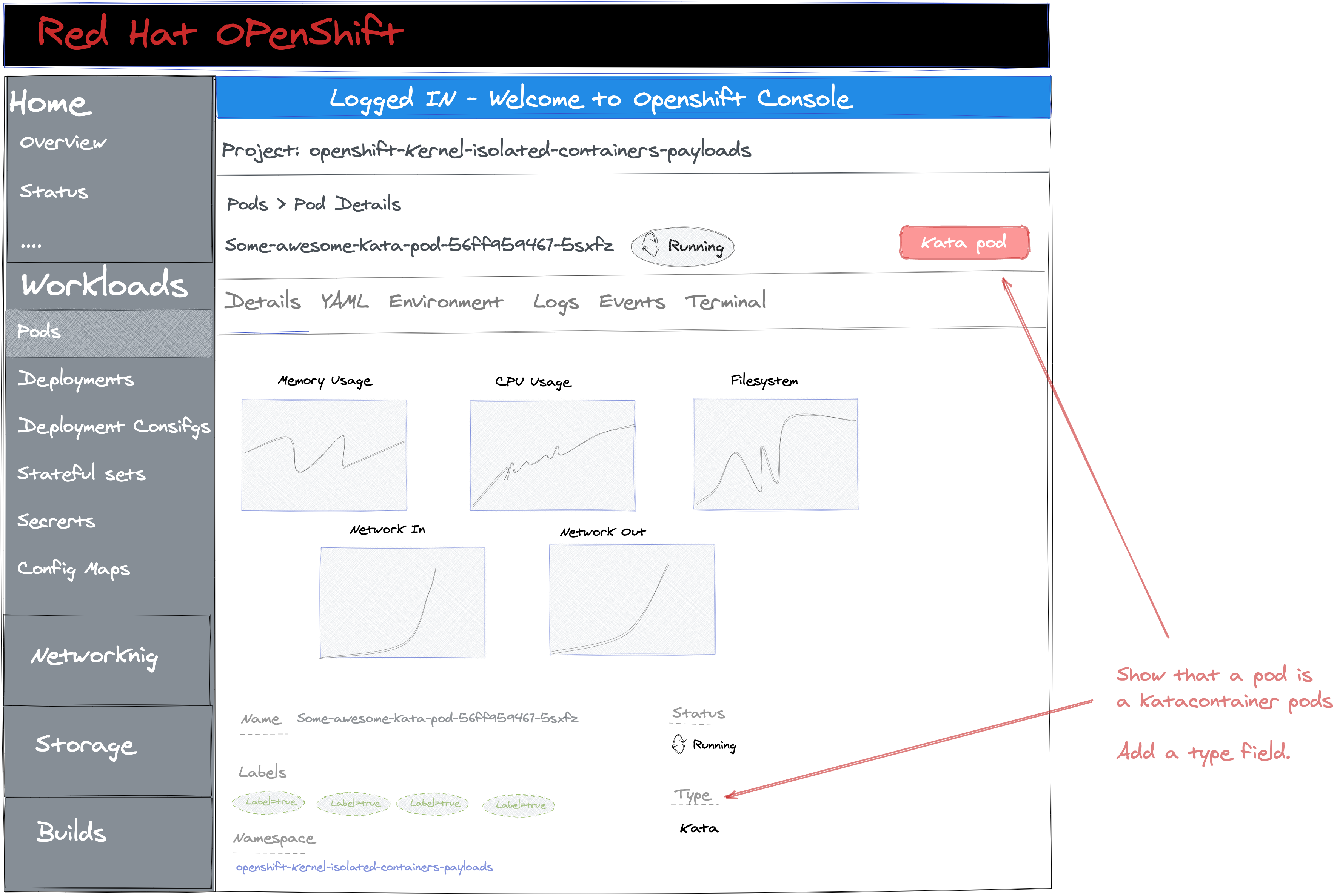
- As a cluster-admin, I would like to be able to differentiate between a normal pod and a Katacontainer pod from the UI.
- As a developer, I would like to create katacontainers-based pods without dealing with YAML, i.e., from the UI.
- As a developer, I would like to switch my deployments to use Kata instead on runC (native).
Requirements
- Kata runtime MUST be viewable when checking running workloads.
- A checkbox or a similar method to create Katacontainers from the UI MUST be provided.
- The above two requirements MUST be tested.

References
[1] https://docs.openshift.com/container-platform/4.6/rest_api/workloads_apis/pod-core-v1.html
We should show the runtime class on workloads pages and add a badge to the heading in the case a workload uses Kata. A workload uses Kata if its pod template has `runtimeClassName` set to `kata`.
Acceptance Criteria:
- Kata runtime must be viewable when checking running workloads, including Pods, ReplicaSets, ReplicationControllers, StatefulSets, Deployments, and DeploymentConfigs.
- Automated test must be written to verify coverage
Andrew Ronaldson indicated that adding a "kata" badge in the heading would be too much noise around other heading badges (ContainerCreating, Failed, etc).